
Audio / Speech Annotation
Audio annotation is a process of labeling the audio files with metadata (i.e) additional information, to train the Natural Language Processing (NLP) model. NLP technology is the ability of machines to understand and interpret human language. This technology has led to the development of various AI models such as intelligent chat boxes, virtual assistants and more.
Audio annotation is done by tagging metadata to the audio recording. This is then converted to machine readable format and fed into the NLP system. This approach doesn’t stop with interpreting human voices, it also aids in the study of instruments, animals sounds and so on. Annotating audio files is a supervised process which requires manual work and specialized annotation tools.
Different types of audio annotation are listed below:
- Speech to Text Transcription - It is the process of converting recorded speech to text. Both the words and sounds are carefully annotated along with correct punctuation. It plays a significant role in search engines.
- Audio Classification - This technique aids in the recognition and differentiation of voices by computers. It is crucial for the advancement of voice-activated virtual assistants.
- Music Classification - Using this technique, instruments and their sounds can be tagged or labeled, which is helpful for organizing in music collections.
- Natural Language Utterance - this method annotates human speech with minute details such as intonation, emotions and more. It aids in machine – Human interaction.
- Emotion Recognition - This approach aims in tracking the voices and its additional details such as speech rate, pitch, pitch jumps, voice intensity and more. This could be interpreted to determine emotions such as anger, happiness, sadness, fear, surprise or neutral thereby supporting customer support operations.
- Speech Labeling - Speech labeling is used to create chat boxes that respond to frequent client inquiries.
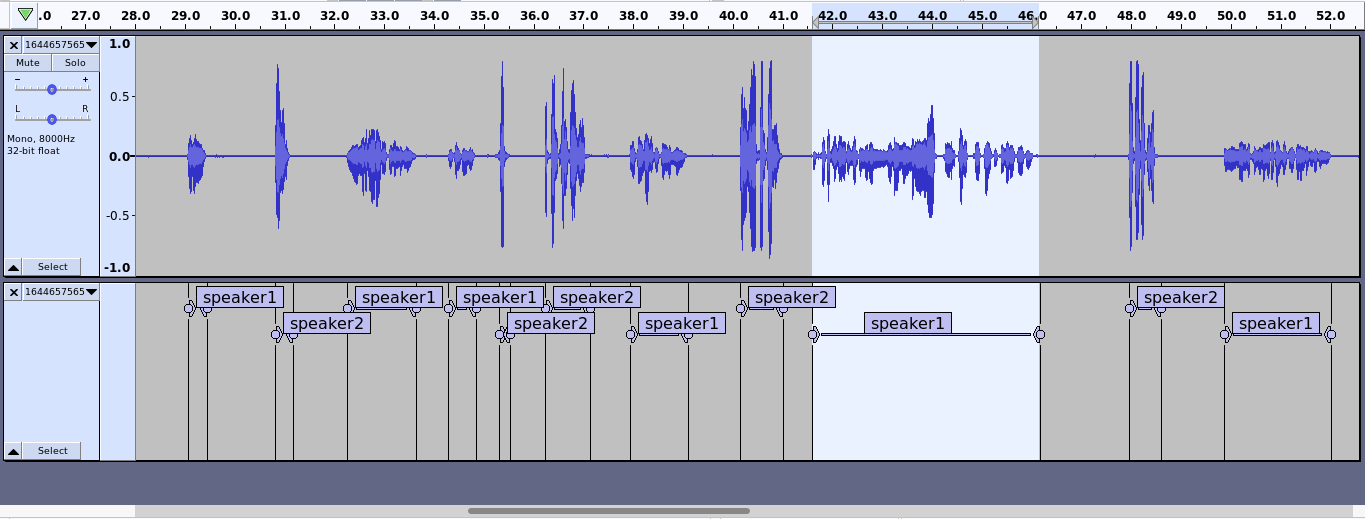
- Speaker Diarization - it is a process of segmentation or clustering the audio in the recording based on the sound source. It helps in identifying the speakers, addressing the query “Who spoke and when”. This approach greatly helps in understanding the conversation better.
At HaiData, we offer a variety of audio annotation services that suits your NLP model requirements. Contact Us today for a free sample annotation!